(Composed with Elasticsearch 7.10 as reference)
Appropriate Scenarios for Similarity Configuration
Elasticsearch commonly serves as a log analysis/management system or full-text search solution. However, in both my previous and current projects, Elasticsearch has been employed for content search scenarios not requiring full-text search capabilities. For instance, requirements such as “Field A matching constitutes primary priority, followed by Field B matching as secondary priority…” involve locating results satisfying multiple sequential conditions. The critical factors concern whether documents match the specified query conditions, rather than the quantity of search keywords contained within documents. However, the default algorithm’s application resulted in scoring influenced by tf and idf parameters, preventing pure ordering by Field A and B scores. Such circumstances necessitate similarity (scoring algorithm) configuration.
Configuration Modification Methodology
Elasticsearch fundamentally employs the Okapi BM25 algorithm (historically TF/IDF) for calculating document scores to determine result ranking priority. The default behavior utilizes this score as the primary sorting criterion. Similarity settings enable modification of this algorithm.
Consulting the official documentation reveals three default algorithms available without additional configuration:
- BM25 ← Default for version 7
- classic ← Former default utilizing TF/IDF algorithm
- boolean ← Selectable when full-text ranking proves unnecessary. Scoring exclusively based on query term matching. Scores are assigned according to query boost values.
Default algorithms are optimized for extracting search results according to keyword importance by calculating factors such as term frequency within documents, prevalence across all documents versus specific documents, et cetera. When complete disregard of such parameters proves acceptable, transitioning to boolean similarity becomes appropriate.
Custom Similarity Definition
Custom similarity definitions with tuned parameters or scripted implementations may be defined and applied to necessary fields. Previous projects necessitated this approach for incorporating tf as the final sorting priority.
Elasticsearch-provided similarity
- The type parameter accepts a type name, with additional options varying by type to specify algorithm formula parameters. (Consult official documentation for available types and options)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18## Example - DFR similarity configuration PUT /index { "settings": { "index": { "similarity": { "my_similarity": { "type": "DFR", "basic_model": "g", "after_effect": "l", "normalization": "h2", "normalization.h2.c": "3.0" } } } } }- The defined my_similarity may be specified during field mapping for targeted application.
1 2 3 4 5 6 7 8"mappings": { "properties": { "my_field": { "type": "text", "similarity": "my_similarity" } } }Parameter modification enables customization of the default BM25 algorithm.
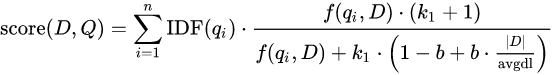
- The documentation presents this formula in script format:
- boost * idf * tf
- idf : log(1 + (N - n + 0.5) / (n + 0.5))
- tf: freq / (freq + k1 * (1 - b + b * dl / avgdl)
- boost * idf * tf
- Parameters k1 and b may be specified.
- https://jitwo.tistory.com/8
- IDF score modification is prohibited; only tf proves adjustable
- The documentation presents this formula in script format:
Scripted similarity
Complete algorithmic implementation via custom scripting remains possible. Without proper expertise, this approach carries risks and requires adherence to specific rules.
Nevertheless, I employed this methodology to eliminate idf influence while preserving tf.
double tf = Math.sqrt(doc.freq); return query.boost * tf- Utilizes the Painless scripting language
- Accessible variables are documented here.
TODO: Recently discovered constant score query appears similar to boolean similarity application; further investigation required.
References
https://www.elastic.co/guide/en/elasticsearch/reference/current/similarity.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
https://saskia-vola.com/when-simple-is-better-the-boolean-similarity-module