This exposition examines execution plans and index utilization across diverse scenarios in comprehensive detail.
6.1. Overview
Execution Plan Definition
The optimizer formulates optimal execution strategies by consulting statistical information regarding data distribution across tables to devise optimal execution plans for query execution.
Query Execution Phases
- Parse SQL statements into MySQL server-comprehensible components (SQL parsing)
- Examine parse tree to determine table reading sequence and index selection (optimization and execution plan formulation by optimizer)
- Retrieve data from storage engine according to selected sequence and indices
Optimizer Categories
- Most RDBMS systems, including MySQL, employ cost-based optimizers
- Generate multiple feasible approaches for query processing, calculating costs for each execution plan utilizing cost information for unit operations and predicted statistical data for target tables
- Rarely employed rule-based optimization exists (establishes execution plans according to optimizer’s built-in priorities. Excludes statistical information such as record counts and column value distributions)
Statistical Information
- Approximate record counts, unique value quantities in indices, et cetera
- Statistical information proves significantly inaccurate for small record counts. Occasionally necessitates forced renewal via analyze command
- analyze command: Updates index key value distribution (selectivity)
- Statistical information collection reads only 8 randomly selected index pages or quantity specified by innodb_stats_sample_pages parameter
6.2. Execution Plan Analysis
- Update, insert, delete statements lack execution plan verification methods. Create select statements with identical where clauses for verification
Execution Plan Column Descriptions
- id column: Each select statement receives distinct id
- select_type column
- SIMPLE: Simple select without subqueries, et cetera
- PRIMARY: Outermost query in statements containing unions or subqueries
- UNION, DEPENDENT UNION, UNION RESULT
- SUBQUERY: Subqueries used outside from clause
- DEPENDENT SUBQUERY: Subqueries utilizing columns defined in outer select. Outer query executes first → subquery execution. Performance degradation
- DERIVED: Subqueries used in from clause
- UNCACHEABLE SUBQUERY, UNCACHEABLE UNION
- table column: Execution plans display per table rather than per unit select query
<derived>or<union>within angle brackets indicate temporary tables- Identical ids: Upper lines constitute driving tables. Driving tables are read first for driven table joining
- type column: Indicates record reading methodology for each table
- const: Unique index scan. Query processing returning precisely one record utilizing PK or unique key columns in where clause
- eq_ref: For join queries. First-read table column values equal-compared with next table’s PK or unique key
- ref: Equal condition searching regardless of joins or constraints
- range: Index range scan! Index searched with ranges rather than single values
- index_merge: Multiple index utilization
- index: Index full scan (reads entire index)
- ALL: Full table scan - most inefficient
- key column: Final selected index displayed
- rows column: Shows approximate record quantities in target tables
- extra column: Performance-related statement displays
6.3. MySQL’s Principal Processing Methodologies
6.3.1. Full Table Scan
Conditions include: extremely small table record counts, absence of index-utilizable conditions in where/on clauses, excessive matching records for range scans
6.3.2. ORDER BY Processing (Using Filesort)
Two approaches for order by processing:
- Index utilization
- Filesort utilization
Filesort employs “sort buffer” memory allocation for sorting operations. When records exceed sort buffer capacity, multi-merge processing with disk temporary storage occurs.
Processing methodologies:
- Index-based sorting
- Driving table-only sorting
- Temporary table-based sorting
6.3.3. GROUP BY Processing
6.3.4. DISTINCT Processing
Common error: DISTINCT applies to entire records, not individual columns
6.3.5. Temporary Tables (Using Temporary)
6.3.6. Table Joins
- Inner joins permit optimizer-controlled join sequence optimization
- Outer joins require outer table precedence, preventing sequence selection
6.4. Execution Plan Analysis Precautions
Critical considerations:
- select_type column: DERIVED, UNCACHEABLE SUBQUERY, DEPENDENT SUBQUERY
- type column: ALL, index (full table/index scans)
- key column: Empty when index utilization fails
- rows column: Substantially larger values than actual record retrieval necessitate query review
- extra column: Various indicators requiring attention
Additional Discoveries During Study
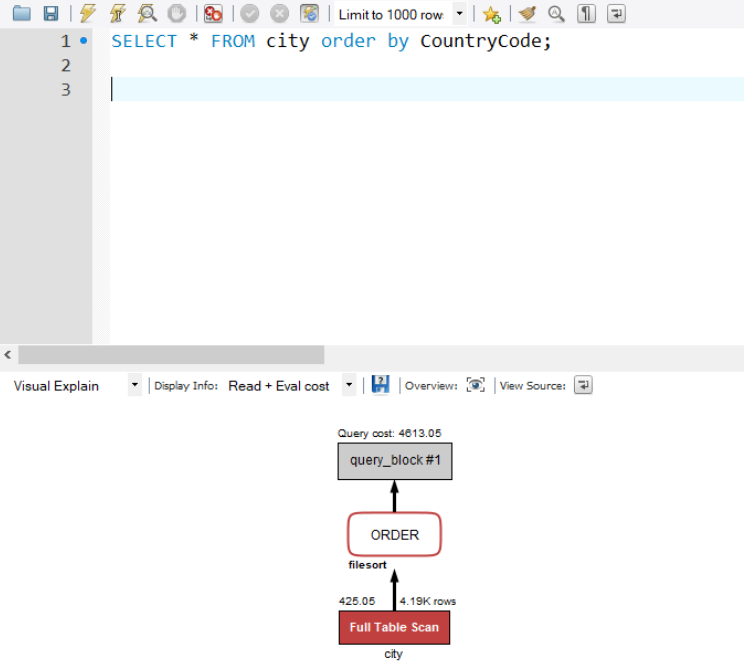
Visual Explain - MySQL Workbench
Workbench possesses Visual Explain functionality. Colors indicate cost (red: high cost, blue: low cost)
Foreign Keys and Automatic Indexing
Foreign key constraint table creation automatically generates indices on specified columns when absent.
Covering Index
Indices enabling data retrieval exclusively from index values without accessing actual storage. Performance enhancement through eliminated storage access!
ICP (Index Condition Pushdown)
extra field displays “Using index condition”. When condition evaluation proves partially feasible using only index columns, condition push-down to storage engine occurs, with storage engine reading tables only when conditions satisfy requirements.
[References omitted for brevity]