실행계획과 여러 상황에서의 인덱스 사용에 대해 상세히 알아보자.
6.1. 개요
실행계획이란
옵티마이저가 쿼리를 최적으로 실행하기 위해
각 테이블 데이터가 어떤 분포로 저장돼있는지 통계 정보를 참조해서
기본 데이터를 비교해 최적의 실행계획을 수립한다
쿼리 실행 절차
- SQL문장을 쪼개서 Mysql서버가 이해할 수 있는 수준으로 분리 (= SQL 파싱)
- SQL의 파스트리 확인하면서 어떤 테이블부터 읽고 어떤 인덱스를 이용해 읽을지 선택(=최적화 및 실행계획 수립 by optimizer)
- 2단계에서 선택된 순서,인덱스로 스토리지 엔진으로부터 데이터를 가져온다
옵티마이저 종류
- mysql을 포함한 대부분 rdbms가 비용기반 옵티마이저(cost-based optimizer) 를 채택함.
- 쿼리 처리를 위한 여러가지 가능한 방법을 만들고, 각 단위 작업의 비용정보와 대상 테이블의 예측된 통계 정보를 이용해 실행계획별 비용을 산출.
- 지금은 거의 안쓰이는 규칙기반 최적화도 있음(옵티마이저 내장 우선순위에 따라 실행계획 수립. 테이블의 레코드 건수, 컬럼값 분포도 등 통계정보 사용 x)
통계정보
- 대략의 레코드 건수, 인덱스의 유니크한 값 개수 등.
- 레코드 건수가 적으면 통계정보가 상당히 부정확. analyze 명령으로 강제로 갱신해야할 때도 있다
- analyze명령: 인덱스 키 값의 분포도(선택도)를 업데이트 함
- 통계정보 수집할땐 랜덤하게 인덱스 페이지 8개 또는 innodb_stats_sample_pages 파라미터 값만큼만 읽어서 수집. (다읽는게 아님ㅋㅋ)
6.2. 실행계획 분석
- update, insert, delete는 실행계획을 확인할 방법이 없다. where절만 같은 select를 만들어서 확인 가능
실행계획에 표시되는 각 칼럼
- id 칼럼
- select문 당 각각 다른 id.
- select_type 칼럼
- SIMPLE - 서브쿼리 등 없는 단순 select
- PRIMARY - union이나 서브쿼리가 포함된 select에서 제일 바깥쪽 쿼리
- UNION
- DEPENDENT UNION
- UNION RESULT
- SUBQUERY - from절 이외에서 사용되는 서브쿼리
- DEPENDENT SUBQUERY - 서브쿼리가 바깥쪽 select에서 정의된 칼럼을 사용하는 경우.
- 외부 쿼리 먼저 → 서브쿼리 실행. 속도가 느리다
- DERIVED - 서브쿼리가 from절에 사용된 경우.
- UNCACHEABLE SUBQUERY
- UNCACHEABLE UNION
- table 칼럼
- 실행계획은 단위select쿼리 기준이 아닌, 테이블 기준으로 표시됨.
< >로 꺽쇠 안에 있는<derived>나<union>같은건 임시테이블을 의미.<derived2>는 id 2번인 실행계획으로부터 만들어진 파생 테이블.- 같은 id라면 윗 라인이 드라이빙 테이블. 드라이빙 테이블을 먼저 읽어서 드리븐 테이블을 조인한다.
- type 칼럼
- mysql서버가 각 테이블의 레코드를 어떤 방식으로 읽었는지
- mysql manual에서는 ‘join type’이라고 소개되어있음
- 어떤 값이 올 수 있는가
- const : unique index 스캔. PK 키나 유니크 키 칼럼을 이용하는 where절로 반드시 1건을 반환하는 쿼리 처리방식 (select * from emp where id = 1)
- 다중칼럼으로 된 키 → const를 못씀. pk의 일부만 조건일때는 ref로 표시됨
- 옵티마이저에 의해 최적화 시 상수화된 후 (쿼리의 결과 자체를 상수화함) 쿼리 실행기로 전달하므로 const란 이름이.
- eq_ref: join을 쓰는 쿼리일때. 처음 읽은 테이블의 컬럼 값이 그 다음 테이블의 PK나 unique 키와 동등 비교 (select * from de, e where e.e_pk = de.empno;)
- ref : join과 상관없이, 제약조건 없이 동등 조건으로 검색 (select * from e where d = ‘1’;)
- 결과가 꼭 1건이 아니어도 됨
- (const, eq_ref, ref 세개는 where절이 동등비교연산자여야함. 성능상 문제x. 매우 빠름)
- fulltext
- ref_or_null
- unique_subquery: where절에 쓰이는 in (subquery) 형태의 쿼리를 위한 접근방식. 서브쿼리에서 유니크한 값만 반환할 때.
- index_subquery: 위와 동일, 중복된 값을 반환할 때. 그렇지만 중복된 값을 인덱스를 이용해 제거할 수 있을 때.
- range: 인덱스 레인지 스캔! 인덱스를 하나의 값이 아닌 범위로 검색할 때 (부등호, is null, between, in, like)
- (( 인덱스를 효율적으로 쓰는 대표적인 방식. const, ref, range를 묶어서 인덱스 레인지 스캔이라고 지칭함 ))
- index_merge: 2개 이상의 인덱스를 이용해 각각의 검색결과를 만들고 merge.
- 여러 인덱스를 읽고 병합하는 과정 때문에 range보다 비효율적.
- AND, OR일때 주로 쓰이는듯한데 연산이 복잡하게 연결되면 제대로 최적화 안된다고 함.
- index: 인덱스 풀스캔. (인덱스를 처음부터 끝까지 다 읽음)
- 비교하는 레코드 수는 풀테이블스캔과 같으나, 인덱스가 크기가 더 작아서 더 빠르게 처리되고, 인덱스가 정렬된 것의 장점을 이용할 수 있다.
- 조건
- (range, const, ref 방식을 못쓰는 경우) && (데이터파일 안읽고 인덱스에 포함된 칼럼만으로 처리가능 || 인덱스를 이용한 정렬이나 그룹핑이 가능한 경우)
- ALL :인덱스 안쓰고 풀테이블 스캔. - 가장 비효율적
- const : unique index 스캔. PK 키나 유니크 키 칼럼을 이용하는 where절로 반드시 1건을 반환하는 쿼리 처리방식 (select * from emp where id = 1)
- possible keys 칼럼
- 옵티마이저가 고려했던 인덱스 후보 목록. 후보..
- key 칼럼
- 최종 선택된! 인덱스를 표시함.
- index_merge를 제외하고 반드시 테이블 하나 당 하나의 인덱스만 이용가능.
- key_len 칼럼
- 인덱스의 각 레코드에서 몇 바이트까지 사용했는지 알려줌.
- 다중칼럼 인덱스일때 유용하다.
- key_len을 보면 다중칼럼인덱스에서 몇개의 칼럼까지 사용했는지 알수 있다
- ((다중칼럼 인덱스가 2개라 치면 2개 다 조건절에 있어야 인덱스를 타는 것이 아님))
- utf8문자 하나가 차지하는 공간은 1~3바이트, 메모리공간 할당은 3바이트로 고정됨
- ref 칼럼
- rows 칼럼
- 실행계획의 효율성 판단을 위해, 대상 테이블에 얼마나 많은 레코드가 포함되어있는지를 통계정보를 참조해 보여줌
- 예측이라서 실제랑 일치하지 않는 경우가 많다.
- 옵티마이저는 이 값을 참고해서 풀 테이블 스캔이랑 얼마 차이가 나지 않는다면 인덱스가 있어도 풀테이블 스캔을 해버릴수도 있다
- 실행계획의 효율성 판단을 위해, 대상 테이블에 얼마나 많은 레코드가 포함되어있는지를 통계정보를 참조해 보여줌
- extra 칼럼
- 성능과 관련된 문장 표시
- Using join buffer
- Using where with pushed condition
- …
6.3. Mysql의 주요 처리방식
6.3.1. 풀테이블 스캔
- fulltable scan 조건
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽기보다 풀테이블 스캔이 더 빠른경우
- where, on절에 인덱스를 이용할 수 있는 조건이 없는 경우
- 레인지스캔을 사용할 수 있는 쿼리지만 조건이 일치하는 레코드건수가 너무 많은경우
- 디스크 읽기 방식
- InnoDB: 특정 테이블의 연속된 페이지가 읽히면 Read ahead 작업이 시작됨(백그라운드 스레드)
- 요청이 오기 전에 미리 디스크에서 읽어 버퍼풀에 저장
- 처음에는 foreground thread가 페이지 읽기를 실행, 특정시점부터는 백그라운드 스레드가 넘겨받아서 한번에 4, 8, … 페이지 읽으면서 계속 수를 증가시키고, foreground스레드는 버퍼풀에 준비된 데이터를 가져다 사용.
- InnoDB: 특정 테이블의 연속된 페이지가 읽히면 Read ahead 작업이 시작됨(백그라운드 스레드)
6.3.2. ORDER BY 처리 (using filesort)
- order by를 처리하기 위한 두가지 방법
- 인덱스 이용 → insert, update, delete쿼리 실행 시 인덱스를 정렬해놓음. 그래서 read는 굉장히 빠르지만 나머지는 느림
- filesort 이용 → 정렬할 레코드가 많지 않으면 filesort로 충분함
- extra칼럼에 “Using filesort"가 표시된걸로 확인
- filesort 정렬 어떻게 함?
- 정렬을 수행하기 위한 메모리 공간 할당받아서 작업 - ‘소트 버퍼’
- 근데 정렬할 레코드들이 소트버퍼 할당공간보다 더 크면??
- 레코드를 여러 조각으로 나눠서 처리. 임시저장을 위해 디스크 사용
- 버퍼 크기만큼만 소트버퍼에서 처리하고 정렬된 결과는 디스크에 임시저장. 그리고 다시 병합하면서 정렬을 수행함. (multi-merge)
- sort버퍼 사이즈: ~1MB. 소트버퍼는 세션메모리영역(여러 클라이언트가 공유 못하고 각각 사용)이므로 커넥션이 많을수록 소트 버퍼 메모리공간이 커짐
- 정렬 알고리즘
- Single pass (usually)
- 소트버퍼에 정렬기준 칼럼 + select되는 칼럼 다 담아서 정렬 수행.
- 더 많은 공간 필요
- Two pass (일부 상황만)
- 정렬 대상 칼럼과 PK만 소트 버퍼에 담아서 정렬 수행, 정렬된 순서대로 다시 PK로 테이블을 읽어서 select할 칼럼을 가져옴
- blob, text칼럼이 select대상일때, 레코드 크기 > max_length_for_sort_data 일때만 사용
- Single pass (usually)
- 정렬의 처리방식
- 인덱스 이용한 정렬
- ORDER BY에 명시된 칼럼이 드라이빙 테이블에 속하고, ORDER BY의 순서대로 생성된 인덱스가 있어야 함. + WHERE절에 드라이빙 테이블의 칼럼에 대한 조건과 ORDER BY는 같은 인덱스를 써야.
- 인덱스의 값이 정렬되어있기 때문에 그냥 인덱스의 순서대로 읽기만 하는 것임.
- ORDER BY에 명시된 칼럼이 드라이빙 테이블에 속하고, ORDER BY의 순서대로 생성된 인덱스가 있어야 함. + WHERE절에 드라이빙 테이블의 칼럼에 대한 조건과 ORDER BY는 같은 인덱스를 써야.
- 드라이빙 테이블만 정렬
- join을 하게되면 결과 레코드 수가 늘어나므로, 조인 실행 전에 첫번째 테이블의 레코드를 먼저 정렬한 다음 조인 실행.
- 조건: 드라이빙 테이블의 칼럼만으로 ORDER BY 절 구성
- where절 만족하는 레코드들 찾기 → sort buffer로 복사 및 정렬 실행 → softbuffer결과와 나머지 테이블 조인
- 임시 테이블을 이용한 정렬
- 조인 결과를 임시 테이블에 저장, 그 결과를 다시 정렬함
- 정렬할 레코드가 가장 많고 가장 느림.
- ORDER BY절 칼럼이 드리븐 테이블인 경우 이렇게 할수밖에 없음
- extra칼럼에 “Using temporary; Using filesort” 가 표시
- 인덱스 이용한 정렬
6.3.3. GROUP BY 처리
6.3.4. DISTINCT 처리
- 실수 주의
- select하는 레코드를 유니크하게 select함. 칼럼을 유니크하게 조회하는게 아님
select distinct first_name, last_name from emp→ (first+ last) 전체가 유니크한 레코드를 가져옴- distinct는 함수가 아니므로 ``select distinct first_name, last_name from emp` 이렇게 해도 first만 distinct 안됨
count(distinct s.salary)와 같은 집합함수 안에 쓰인건 그 컬럼에 대한 유니크한 것들 가져오는 거
6.3.5. 임시 테이블(using temporary)
6.3.6. 테이블 조인(!)
inner join은 어느테이블을 먼저 읽어도 결과가 달라지지 않음 - 옵티마이저가 조인 순서를 조절해서 최적화.
outer join은 outer 테이블을 먼저 읽어야해서 순서를 선택할 수 없음
inner join
1 2 3 4 5 6 7 8 9for (record1 in table1) { // outer table(driving table) - 먼저 읽혀야 for (record2 in table2) { // inner table(driven table) if (record1.join_column == record2.join_column) { join_record_found(record1.*, record2.*); } else { join_record_notfound(); // 짝을 못찾으면 조인결과에 포함 x } } }outer join
1 2 3 4 5 6 7 8 9for (record1 in table1) { // outer table(driving table) - 먼저 읽혀야 for (record2 in table2) { // inner table(driven table) if (record1.join_column == record2.join_column) { join_record_found(record1.*, record2.*); } else { join_record_found(record1.*, null); // 짝을 못찾아도 table2 칼럼을 null로 채워서 가져옴 } } }- outer table의 결과를 버리지 않고 결과에 그대로 포함
- 주의: outer join에서 join되는 드리븐 테이블에 대한 조건은 where절 말고 left join의 on절에 모두 명시해야함 (그렇지 않으면 옵티마이저가 outer join을 내부적으로 inner로 바꿔버림..)
- inner join으로 바뀌는 쿼리:
select * from emp e left outer join sal s on s.emp_no = e.emp_no where s.salary > 5000; - → on절에 sal테이블이 없어서 inner join으로 바뀌어버림
- how to fix?
select * from emp e left outer join sal s on s.emp_no=e.emp_no and s.salray > 5000
- inner join으로 바뀌는 쿼리:
join buffer를 이용한 조인
join할 때 드라이빙 테이블에서 일치하는 레코드 건수만큼 드리븐 테이블을 검색함.
- → 드리븐 테이블은 여러번 읽음.
- → 드리븐 테이블 검색 시 인덱스를 못쓰면 엄청 느려짐
- 근데도 드리븐 테이블에서 풀테이블 스캔, 인덱스 풀스캔을 해야한다면
- 드라이빙 테이블 레코드를 메모리에 캐시한 후(join buffer에 저장) 드리븐 테이블과 메모리 캐시를 조인하는 형태로 처리함.
- 드리븐 테이블을 먼저 읽고 조인버퍼에서 일치하는 레코드를 찾는 방식이 됨
- → 정렬 순서가 흐트러질 수있음
- 드라이빙 테이블 레코드를 메모리에 캐시한 후(join buffer에 저장) 드리븐 테이블과 메모리 캐시를 조인하는 형태로 처리함.
outer join과 inner join은 성능상으로는 큰 차이 없음. 성능이 아니라 업무 요건에 따라 고려하자
6.4. 실행계획 분석 시 주의사항
- select_type 칼럼
- DERIVED
- from절에 사용된 서브쿼리로부터 발생한 임시 테이블. - 데이터가 커서 임시테이블을 디스크에 저장하면 성능이 떨어짐
- UNCACHEABLE SUBQUERY
- 사용자 변수나 일부 함수 사용 시 서브쿼리를 캐시 못함.
- DEPENDENT SUBQUERY
- 서브쿼리가 외부 쿼리 결과 값에 의존적인 경우. 전체쿼리 성능을 느리게 함. 외부쿼리와의 의존도를 제거하는게 좋다.
- DERIVED
- type 칼럼
- ALL(fulltable scan), index(index full scan) → 전체 레코드 대상 작업 방식이라 느리다.
- key 칼럼
- 인덱스 사용을 못할 때 이 칼럼이 비어있게 됨. 인덱스 추가하거나 조건을 바꾸자.
- rows 칼럼
- 실제 가져올 레코드 수보다 훨씬 큰 값이 표시된다면 쿼리를 재검토하자.
- limit가 포함된 쿼리라도 limit의 제한은 rows 고려 대상에서 제외됨 주의.
- extra 칼럼
- 쿼리가 요건을 제대로 반영하고 있는지 확인해야하는 경우(성능과의 관계보다는 쿼리가 틀렸을 가능성)
- full scan on null key
- impossible having/where/ where notice after reading const tables
- No matching min/max row
- No matching row in const table
- Unique row not found
- 쿼리의 실행계획이 좋지 않은 경우(쿼리를 더 최적화할 여지가 있을 수 있다)
- Range checked for each record
- Using filesort
- Using join buffer
- Using temporary
- Using where - rows칼럼 값이 너무 크지 않은지 확인
- 쿼리의 실행 계획이 좋은 경우
- Distinct
- Using index
- Using index for group-by
- 쿼리가 요건을 제대로 반영하고 있는지 확인해야하는 경우(성능과의 관계보다는 쿼리가 틀렸을 가능성)
책 읽다가 & 인덱스 관련 찾아본 것
visual explain - mysql workbench
워크벤치를 써도 그냥 explain~ 문을 실행시킨 결과로 확인을 했었는데 검색하다가 visual explain 기능이 있는걸 발견했다. 복잡한 쿼리일수록 유용한 기능일듯!!!
(빨간색에 가까울수록 비용 높고 파란색에 가까울수록 비용 낮음)
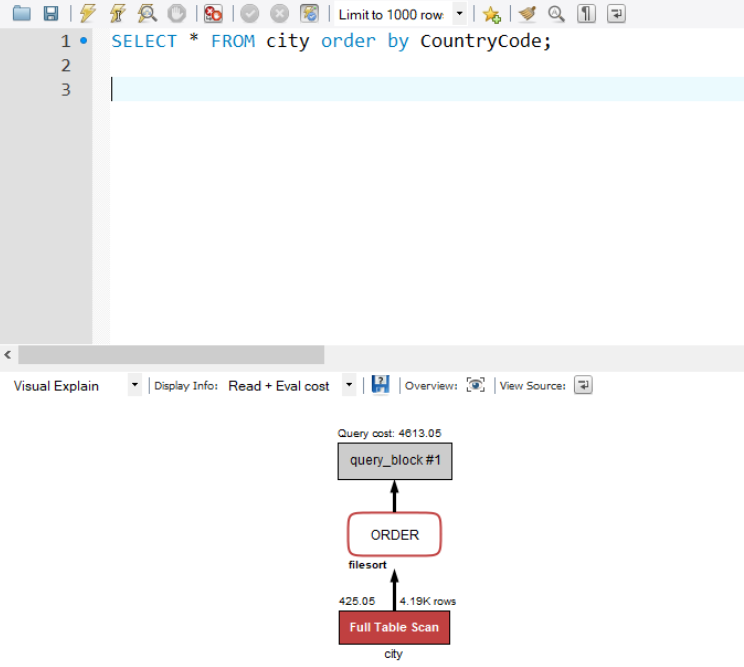
https://engineering.linecorp.com/ko/blog/mysql-workbench-visual-explain-index/
foreign key는 자동으로 인덱스가 되는가
⇒ 된다.
외래 키 제약조건이 있는 테이블을 생성할 때 지정된 열에 인덱스가 없는 경우 생성.
Covering index는 무엇인가
- index에 있는 값만으로도 데이터를 가져올 수 있는 인덱스. 실제 데이터가 있는 저장공간까지 접근할 필요 없어서 성능향상!
- select, where, order by 등에 사용되는 모든 컬럼이 인덱스의 구성요소일때.
- 실행계획의 extra필드에 “Using index”
https://gywn.net/2012/04/mysql-covering-index/
ICP(Index Condition Pushdown)는 무엇인가
- extra필드에 “Using index condition”
- 인덱스의 컬럼만 사용하여 조건의 일부를 평가할 수 있는 경우 그 where조건을 storage engine까지 가져가서(condition push down), storage engine은 조건이 충족된 경우만 테이블에서 읽음.
- 다른 말로 설명: 조건에 인덱싱된 컬럼과 인덱싱 되지 않은 컬럼이 포함되어있고, 인덱스에 포함 된 컬럼 값의 정보를 사용하여 검색 할 레코드를 필터링해서 찾는다.
- storage engine이 기본 테이블에 접근하는 횟수를 줄일 수 있다.